Git Reference Guide - Part One
Published Jan 21, 2019
Reading time 7 minutes
Getting to Grips with Git
The basics
Git is a Revision Control System, a tool to manage your source code history. GitLab (or GitHub) is a service to manage the projects that use git.
I massively recommend reading the git book for a full understanding of how git works under the hood, it’s also a great reference for everything git.
A great trick to remember with git is that there’s a good help guide for every command. If you’re ever not sure, firstly run git help and if you need a bit more info - check the git book.
$ git <command> -h
Note, for my examples, type everything after the $ and replace between the <> with your specific need. The above example would be git add -h to see the help for the git add command
Why would you use git?
Have you ever had a lovely working bit of code and you need to add some more stuff to it? So because you’ve been in this predicament before you save a copy of the code in a safe place so you know you can always go back? At its most basic - this is what git is doing.
Then if you’re working with other people, they might be doing one bit of new code and you’re doing some other bits, at some point, you’d need to get both sets of changes into one (hopefully) working copy of the code that you can both access. Viola - git to the rescue!
How does it work?
Git saves everything in a local database in your project root - the .git file. When you clone a repo, this is what contains all the information and history of the project.
Git remembers the changes you’ve made to the files by taking snapshots at every change - like at a commit for example. If a file hasn’t been changed then there’s no point in saving it again so it saves the files that have changed and a reference to the unchanged files so they’re not saved again.
It’s a bit like if you just copied your index.html file to a safe space before playing around with it. You know that’s the only file you’re changing at the moment and you might want to go back to how it was before you started playing around with it.
All this information is in your .git file locally which makes it incredibly fast.
Git saves information by using checksumming - basically squishing it all through an SHA-1 hash and then comparing it against the last time it was squished, if it’s the same, then no change so no new save is needed but if it’s different - it saves a new revision.
The checksums are then used to create the history of the project. All of the checksums plus some more information about the time and the committer is saved along with the previous, parent(s) commit. This keeps a cryptographically true history.
This is what a hash looks like, you may recognize it from using git and on GitLab/GitHub.
24b9da6552252987aa493b52f8696cd6d3b00373
Git uses the commit hash to find changes saved against it, a key-value data store system. It’s explained in more detail in the git book but don’t be afraid to go and have a look in your .git directory - try looking through the logs at the refs to see how the hashes are used or run this command to see what your master branch looks like.
$ git cat-file -p master^{tree}
To command line or not to command line
I use the command line, usually Git Bash on Windows or through my terminal on Ubuntu. The best reason for this is explained perfectly in the git book:
… the command line is the only place you can run all Git commands — most of the GUIs implement only a partial subset of Git functionality for simplicity. If you know how to run the command-line version, you can probably also figure out how to run the GUI version, while the opposite is not necessarily true. Also, while your choice of graphical client is a matter of personal taste, all users will have the command-line tools installed and available.
Form my experience an additional benefit of using the command line is that you can press up and see what commands you ran and where so if you get confused it’s easy to see what you did and figure out how to unravel it. With a GUI, once you’ve pressed a few buttons (cos you know, what’s the worst that can happen!?!!) it can be quite tricky to know what you pressed.
Sounds cool, how do I use it?
Using git locally, there are three stages to remember for the basic workflow.
To demonstrate the three stages of git, here’s my current git status whilst I’m writing this post. I’m on a branch called post/git-the-basics and I’ve already done one commit. Git command line is awesome for telling you what you can do next, there’s loads of helpful information at each stage and remember you can always run -h against a command if you’d like a bit more info.
-
Working Tree
This post is being tracked by git and it knows I’ve made modifications to the file, I can now add these changes. I’ve also got a new file (the below picture) which git doesn’t know anything about yet - it’s not being tracked. I can add it and then it’ll start being tracked by git.
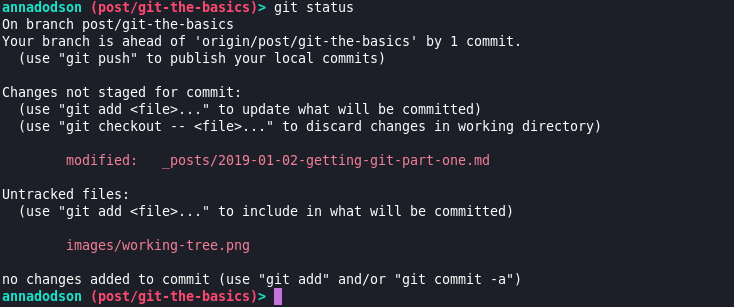
-
Staging Area
I’ve made my changes and I’m ready to save my work, I want to make sure it’s backed up and I might finish writing this on my laptop instead of my desktop. Once I’ve added my changes, it’s staged ready to be committed. This stage can also be called the index, imagine it to be like the first item in a list.
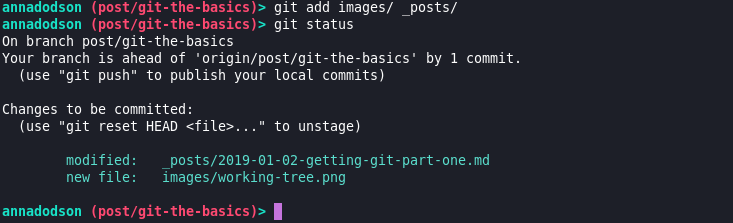
-
Git Directory
I’ve committed my changes, they’re now in my local git directory and saved against a hash. I can now keep making changes or revert back to that state.
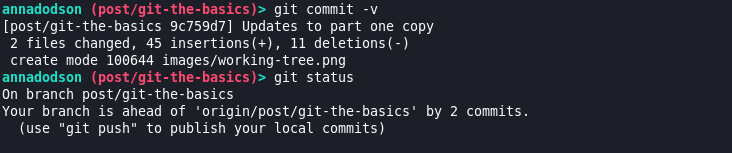
Once my git directory is updated, I can push to GitLab so the changes aren’t just on my local computer anymore but are also backed up and accessible from another device or to anyone else working on the project.
When I push my changes, it knows where to go because I set the remote when I initialized the project. My data is sent to GitLab via ssh.
Why use SSH over HTTPS?
Typically, SSH (Secure Shell) is used for interacting with your git server, mainly because it’s efficient, fast, secure and most systems already have ssh running or can run it easily. The problem with SSH is users need to have SSH keys set up on the server to gain access to the repositories but once keys are set up it’s very easy.
HTTPS is also fast and secure but can take a bit more configuring than SSH on the server side but for the end user, it’s simpler. HTTPS is a good way to get anonymous access to repositories but can ask for authentication when it’s required, for example: pushing code to the repository. Having to enter your credentials every time can be annoying.
GitHub and GitLab offer both SSH and HTTPS protocols to use.
I use SSH, mainly because when I started learning git, that’s what everyone else was using! Now, it’s second nature to me and I don’t have to worry about authenticating again once my keys are set up. Plus, it’s good to practise using SSH!
Where now?
In my next post, I talk through setting up a new git repo and pushing to it. When I started using git, I had some private repos to just practise with and if I got in a pickle on a real repo, I’d replicate the mess on my private repo and run through trying to fix it before repeating on the real repo. Git’s a hugely powerful tool and you can do amazing stuff with it so it can get complicated - don’t worry, there’s loads of resources online, stack overflow questions and people to help.
Resources
git book - https://git-scm.com/book/en/v2
git documentation - https://git-scm.com/docs
SHA and hashing - https://computer.howstuffworks.com/encryption5.htm
SSH - https://www.ssh.com/ssh/